微软研究院在IJCAI2016的Tutorial中阐述了自己在深度学习、深度神经网络中的应用,第二部分是在统计机器翻译和会话中的应用,第三部分是选择了自然语言处理任务的连续表现。 第四部分是自然语言的理解和连续语言词的表达。
联合编辑:李尊、章敏、陈岑
自然语言理解的重点是建立能够和使用自然语言的人进行对话的智能系统。 其研究课题:1)文本语义表现2 )支持有用的推论任务。

连续词语的表达方式如下:
l创建多个单词向量的流行方法
l编码条件共存信息
l测量语义相似的井
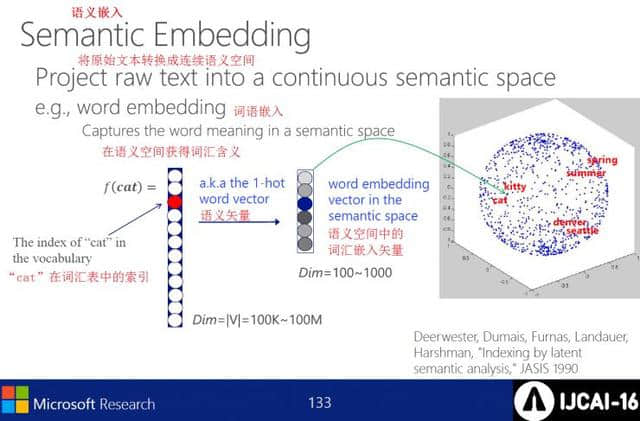
语义嵌入将原始文本转换为连续的语义空间

嵌入有效的原因包括:
l词汇语义词的相似度
l文本的简单语义表达
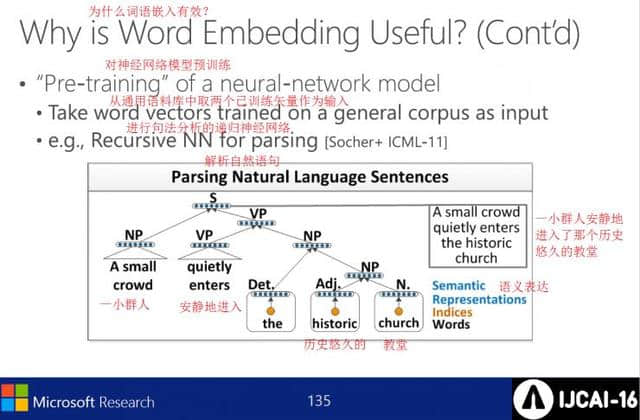
预先训练神经网络模型

语言嵌入模型的样本、评价及相关工作
潜在语义分析包括SVD摘要原始数据、与同义词典没有明确关系的术语向量投影k维潜在空间、词类似度等
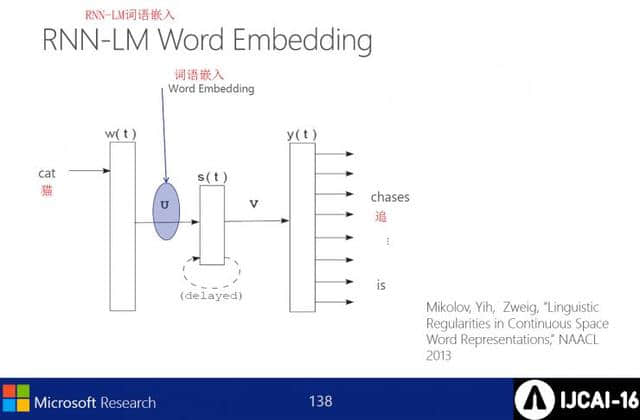
RNN-LM语言嵌入

SENNA语嵌入
嵌入CBOW/Skip-gram语言
![]()
DSSM :学习语义
0

GloVe :语言表达的全局向量
语义相关度可以从词的共现次数的概念来看

评价:语义词的相似度
l数据:人的判断短语
l词相似度排序与人类判断的关系
l独立语义嵌入模型通常不能实现最佳结果

评估:关系相似度
判断两个组词是否有相同的关系,为什么有效
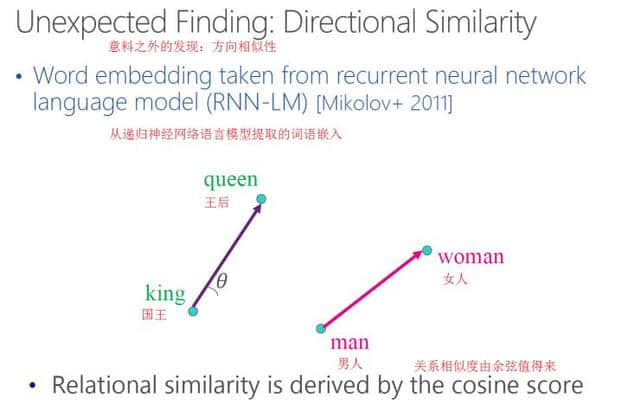
意外发现:嵌入从递归神经网络的语义模型中提取的词语,关系的相似度从馀弦中有价值。
实验结果

其他数据集中的相似结果
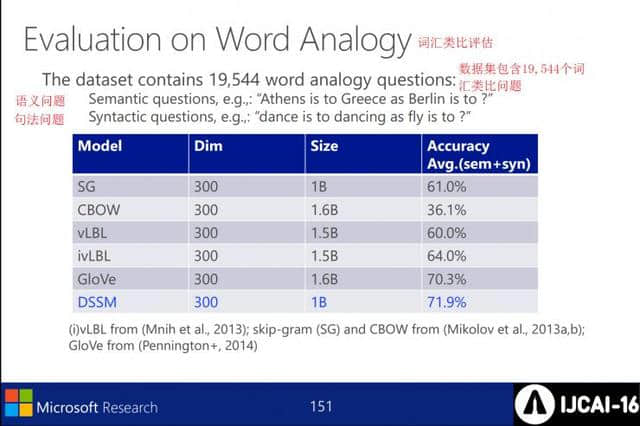
词汇类比评价。

讨论。 1 .方向相似性不能处理语义关系2 .向量计算=相似性计算3 .在计算中找到最接近的x。

模拟不同的词汇关系,如判断几个相关工作是同义词还是同义词。

相关工作―词汇嵌入模型:评价其他词汇嵌入模型Word2Vec的分析和方向相似性理论论证和统一NLP的向量空间表现。
0
神经语言的理解。
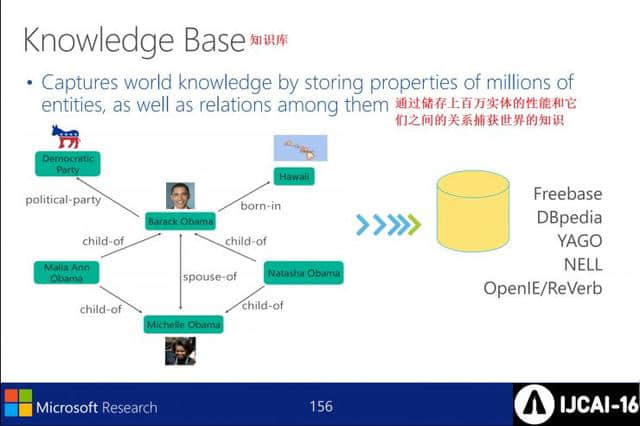
知识库:通过存储数百万实体的性能及其关系,获得世界知识。

现在KB在NLP&IR中的应用——回答提问、信息提取、网络检索。

知识库推理-知识库不完整,模拟多关系数据,知识库的嵌入效率和精度高。

基于知识的嵌入: KB中的每个实体都由Rd向量表示,并且预测fr(Ve1,Ve2 )中的( e1,r,e2 )是否正确。 KB嵌入的工作:张量分解,神经网络。

张量分解-知识库表示(1/2) :收集-主-谓词-宾-(e1,r,e2 )

张量分解-知识库表示(2/2):0输入表示不正确
张量分解对象
衡量关系的程度

输入张量分解:关系的主要知识是输入信息、约束和损失中唯一合法的实体。 利用输入信息的优点在于,模型训练时间短,KB可扩展大,预测精度高。
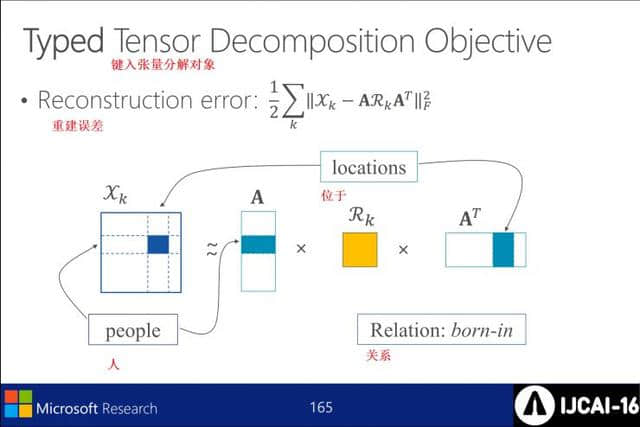
输入张量分解对象的重构误差
加上张量分解对象的重构误差

培训过程-交替最小二乘法
0
实验: kb完成
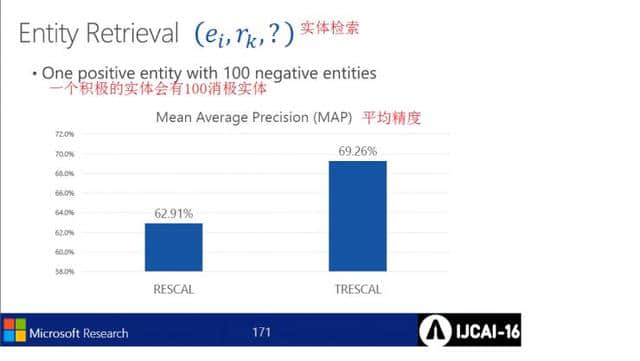
实体检索
基于相关性的检索及其平均精度
基于知识的嵌入模型

相关操作的评估函数及其参数
神经网络KB嵌入方法的经验比较:参数越少,双线性运算符越重要。在建模时,乘法运算必须优于加法运算。pre-trained子句和嵌入向量对于表示非常重要。

喇叭节最小化规则

在相关的路径上学习
自然语言理解
连续词语表达与词汇语义学
基于知识的嵌入
基于KB的问题回答与机器理解
语义分析
非常困难的语言任务可能会导致严重的错误

非常困难的语言任务可能会导致严重的错误

非常困难的语言任务可能会导致严重的错误
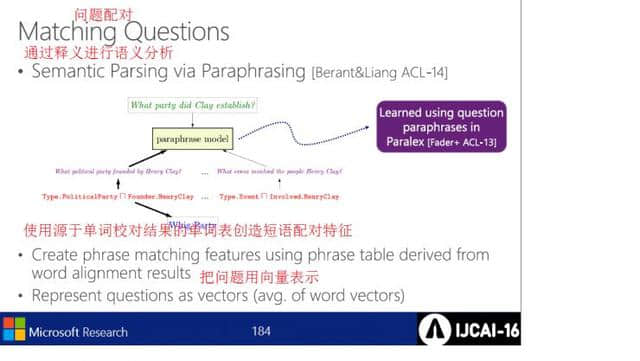
在问题对中,使用基于释义的语义分析和基于单词校正结果的单词表,用向量表示创建短语对的特征的问题。
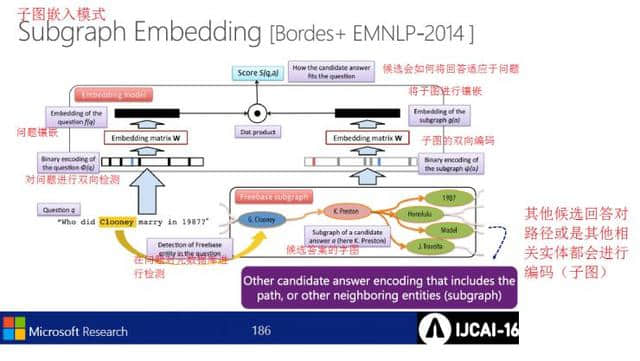
马赛克模式
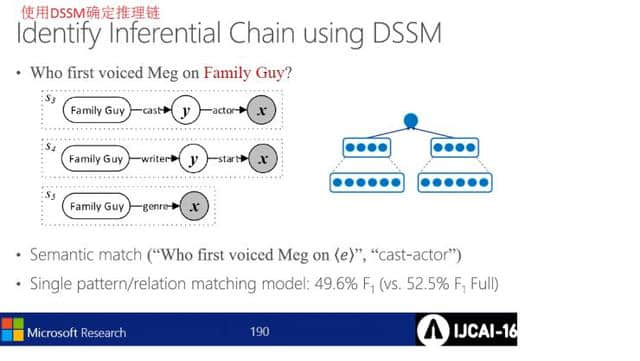
用DSSM确定推理链
0
深入学习的回答和问题数据集。
比较了原始版本和匿名版本。
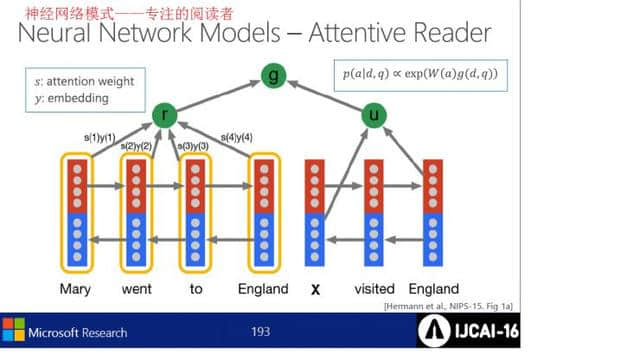
神经网络模型中Attentive Reader的具体运行结构图。
神经网络结构中Impatient Reader的执行结构图。
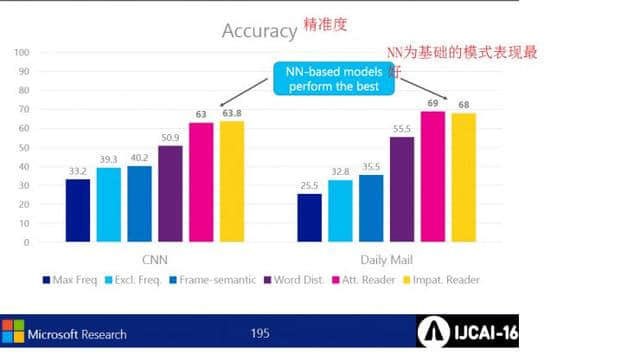
各模式的执行结果的精度的比较,其中以NN为基础的模式表现得最好。

对所有问题进行了全面的检查,但问题是用智能的方法制作大规模的监视对象数据,明确理解度的问题。 另外,好消息是实体能够平等工作,积极reader模式表现最好。 坏消息任务难度大,需要优化( 25%的问题回答不出来)。

连续空间表达对一些神经网络的语义理解任务有帮助,如连续词表达和词汇任务、知识库马赛克、基于KB的问题回答和机器理解。
在NN和连续表达方面实现了很大的进步,如文本处理和知识推理。
关于未来的展望,提出了以下几点建议
创造共同的智能空间
文本、知识、推理等
从零件模式到端到端解决方法。
总结:
自然语言理解的重点是建立能够和使用自然语言的人进行对话的智能系统。 此外,连续词表达和词汇语义学是必要的。
连续词表达着重于知识基础的嵌入和基于知识基础的问题回答&机器理解。